
Abstract
This paper proposes a new pattern in the text of the Voynich Manuscript named the “Curve-Line System” (CLS). This pattern is fundamentally based on shapes of individual glyphs but also informs the structure of words. The hypotheses of the system are statistically tested by two independent people to judge their significance. It is also compared to existing word structure paradigms. The results suggest that the shapes of glyphs affect their placement in a word, the Curve-Line System is an intentional feature of the text design, and the text of the Voynich Manuscript is a highly artificial system.
Introduction
The Curve-Line System (CLS) is a pattern in the Voynich Manuscript that I have been thinking about every now and again, as an extension of something that Prescott Currier briefly commented on but did not look into. Extensive research and discussion show that while glyph shapes and word construction have been looked at thoroughly, the connection between the two topics has not been investigated to this level.
In this article I will describe the Curve-Line System, test it with statistics, compare it with other word structure paradigms and discuss its significance. The statistics are independently investigated by David Jackson with different transcription and tools to ensure that results are not particular to my transcription file or methodology.
The article assumes prior knowledge about the Voynich Manuscript and first-year university statistics. But no fear if you don’t understand the statistics jargon, you will still be able to skim the statistical sections and get the gist. Prior knowledge of other Voynich Manuscript word structure paradigms is helpful but not required.
The article is split into separate parts to cover the four independent but related components of the Curve-Line System – the glyph construction, the glyph affinity, the word structure, and the explanation of the discrepancies. Each section has its own explanation and thorough statistical tests to build it up in a linear fashion. It is quite long and the theory may initially seem shaky but I assure you, patience is needed; everything will unfold and fit together nicely by the end.
Notes on conventions
This article uses EVA transcription.
This article uses the Anglosphere convention for decimal numbers. A dot (“.”) is used for decimal points and a comma (“,”) to delineate groups of three digits. For example, the number “one thousand point five” is denoted as 1,000.5. (please notify me if anything breaks this convention!)
1. PART 1 – CLS glyph construction
1.1 Introduction to Voynich Manuscript glyphs
The text of the Voynich Manuscript is composed of a limited alphabet of glyphs. While there are disagreements over the specifics of this alphabet (e.g. which glyphs are variants or ligatures and which ones are separate), there is consensus on two facts: the alphabet in its entirety has not been found in any other document, and many of the glyphs have similar shapes. Some informal classifications have been made based on these shape similarities. One example is shown below. This selected is based on the most common forms of glyphs in the EVA system.
There are the gallows:

Benches:

Benched gallows: (which may be ligatures)
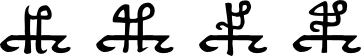
Vowels (resembling lowercase Latin a, e, i and o):
And everything else in the main EVA character list:
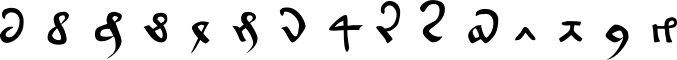
While there are clear design choices for the gallows, benches, benched gallows and vowel glyphs, the remaining collection does not appear so easy to group. The Curve-Line System proposes a design scheme for many of the glyphs in the “everything else” category above.
1.2 Proposed glyph construction system
In the proposed glyph construction system, we start with one of two base shapes, a curve or a line.

We then append a tail modifier to the base shape. There are four options shown below, where the dotted circles are placeholders for the base shape. The tail modifier attaches to the bottom or top of the base shape.
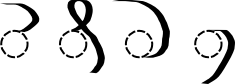
All eight possible combinations are shown in the table below. All of them are real EVA characters, although the one in the bottom right is not easy to recognise at first glance.
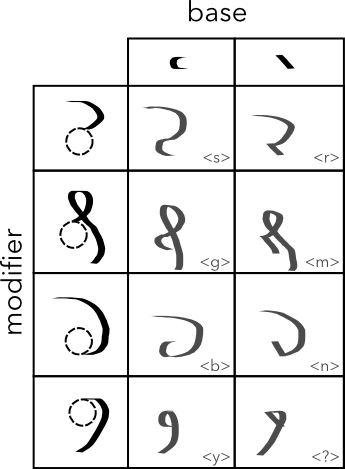
After manually investigating the glyphs in the Voynich Manuscript scans, it is plausible that the combination in the bottom-right represents the “l” character.
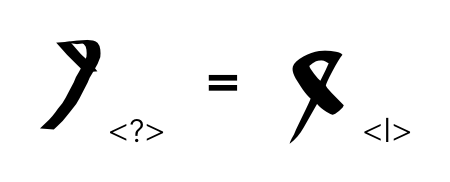 Look closely at the “l” in the example below. It starts with an “i” then a curved tail from the top like my modifier table suggests. You can see many others with this shape in the manuscript.
Look closely at the “l” in the example below. It starts with an “i” then a curved tail from the top like my modifier table suggests. You can see many others with this shape in the manuscript.

The significance of this will become clear.
2. PART 2 – CLS glyph affinity
2.1 Like attracts like
Each shape in the table comes in pairs. There is the variant based on a curve base (the left column) and the variant based on a line base (the right column). There appears to be a connection between these base shapes and the shapes of other glyphs. For example, consider “b” and “n”. We know that at the end of words, “b” comes after “e” and “n” comes after “i”, but not the other way around.

Notice how the two glyphs constructed from curves go together, and the same applies for the ones constructed from the small straight line.

Can we quantify this? And does this apply for the other glyphs in the table?
2.2 Statistical test for CLS glyph affinity
2.2.1 Hypothesis
For these tests, a word is defined in the traditional sense, a sequence of text delineated by spaces. A glyph is a character in the Voynich Manuscript text according to some convention. Multiple EVA characters may be used to define one glyph.
The glyphs in the modifier table can be split into two groups: the curve-glyphs (i.e. those with the curve base-shape in the left column) and the line-glyphs (i.e. those with the line base-shape in the right column).
The glyph affinity section suggests that curve-glyphs must be preceded by the curve vowel “e” and not the line vowel “i”. Conversely, line-glyphs must be preceded by the line vowel “i” and not the curve vowel “e”. For example, “-ir” is conforming but “-er” is nonconforming; “-es” is conforming but “-is” is nonconforming; and so on. (write these out in the original script and it should be clearer).
I hypothesise that conforming combinations will outnumber the nonconforming combinations by at least a factor of 2 in every case.
2.2.2 Gear
To ensure accuracy of results, the hypothesis was tested by two people independently with different transcriptions and tools. This was done to ensure that results reflected the statistics of the underlying text and were not particular to one person’s transcription file or methodology.
I used the majority-vote EVA transcription and prepared it by stripping away metadata, marginalia, the dash character (“-“), interlinear non-coding spaces (i.e. “!”), unreadable words (i.e. those with “*”), weirdos (i.e. those with “&”), and filling in ambiguous spaces (i.e. converting “.” to a space). To gather data I used regexes in Notepad++ and programmed in Python. Follow-up calculations were done in SPSS and Microsoft Excel.
David Jackson used Takeshi Takahashi’s EVA transcription. He prepared the transcription by stripping away the metadata and dash character. He programmed in ColdFusion and Java.
This set of gear was used across all statistical tests, so this section will not be repeated later in the article.
2.2.3 Method
For this section of the theory, both people used the same basic method but programmed it differently. Both people tested the entire manuscript, but David also tested on the Currier languages A and B separately.
Each person tested the hypothesis by using an automated method to scan all the words in a transcription of the Voynich Manuscript. If a word ended with s, r, l, y, g, m, b or n, and was preceded by e or i, it was added to the appropriate tally. Only word endings were considered because many of these glyphs only occur at the end of words. Neither person was allowed to share information or code until finished. After results were collected, the totals, means and conforming/nonconforming ratios were calculated and compared.
David chose to count the “-in” ending separately from “-iin” to prevent discussion over whether ii is a separate glyph and to prevent possible transcription errors.
Due to the small sample size of combinations, no formal statistical analyses were used.
2.2.4 Data (Brian Cham)

Brian’s result data table for Part 1 statistical test about glyph affinity.
2.2.5 Data (David Jackson)
David tested Currier A and Currier B sections of the manuscript separately (full results omitted for brevity). Here are his aggregate findings.
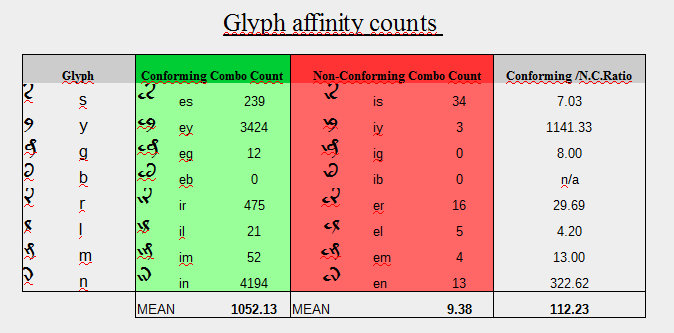
David Jackson’s results for the CLS part 1 glyph affinity test (aggregate).
2.2.6 Interpretation
Both test results are roughly in concordance. In every case the conforming combinations (n=8) outnumber the nonconforming ones, even with possible transcription errors in play. The mean of the conforming combinations greatly outnumbers the mean of the non-conforming combinations by a factor of 110.42 (112.23 in David’s test).
The largest difference is -y, where conforming outnumbers nonconforming by 665.17 (1141.33 in David’s test). The only cases where the conforming/nonconforming factor was under 5 was when the sample size was low, i.e. under 50 words.
Note that in our transcription files, the glyph “-b” did not occur. However, looking manually at the occurrences of nonconforming “en” in the scans showed that these were all conforming “eb”, which increases the difference even further.
Based on these results, I conclude that there is a meaningful difference between these conforming and nonconforming combinations depending on the base shape of the glyph.
2.3 Implications
If this part of the theory is true and comprises a hard and fast rule of Voynichese text, it may help with solving ambiguities in digital transcription. For example, consider the nonconforming ending “-el” in f84v.
 Is this “chee” followed by a loopy “l” or a malformed “y”? From the like-attracts-like rule we can say that the last letter is more likely to be the curved variant “y” because the preceding “e” is the curved vowel.
Is this “chee” followed by a loopy “l” or a malformed “y”? From the like-attracts-like rule we can say that the last letter is more likely to be the curved variant “y” because the preceding “e” is the curved vowel.
3. PART 3 – CLS word structure
Here’s where things get more interesting but more speculative.
3.1 Shape-based glyph classification
Considering the above, we can classify the entire alphabet according to each glyph’s base shape. Here are the ones constructed from a curve:

Here are those constructed from a line (the small backwards sloping “i” line, not just any line):

Here are those constructed from both:

And everything else in the EVA list:
3.2 Mind-blowing fact of the day
The first letter of “curve” is “c” which is shaped like a curve. The first letter of “line” is “l” which is shaped like a line. This has nothing to do with my hypotheses, I just thought it was cool.
3.3 CLS word structure proposal
3.3.1 Abbreviations and terminology
Curve-glyphs are glyphs with a curve as the base-shape, i.e. those in the first part of the new classification above. Line-glyphs are glyphs with the short diagonal line as the base shape, i.e. those in the second part of the new classification. With respect to the modifier table in part 1, and the basic vowels “e” and “i”, the curve-variant is the curve-glyph counterpart and the line-variant is the line-glyph counterpart.
[c] stands for any curve-glyph. [l] stands for any line-glyph, [a] stands for any glyph constructed from both, and [E] for anything else.
We can combine this notation to describe whole words, e.g. [lllc] means “a word with three [l] glyphs then one [c] glyph”. This notation is called the curve-line pattern of a word.
3.3.2 Word structure hypothesis
The basic hypothesis is that everything should follow the shape-based affinity.
Voynichese letters are intolerant and only want to live next to another of their own type. [c] must be next to [c]. [l] must be next to [l]. [a] counts as [c] on its left side and [l] on its right side, since all of these glyphs have a curve on the left and a line on the right (none are the other way around*).
However [E] is invisible; letters see the letters past them. They may also be called “transparent“.
*With the possible exception of the rare connected “ikh”, “ith”, “ifh” and “iph” characters if they are real glyphs.
3.3.3 Hypothetical examples
Words with curve-line patterns [ccc] and [lll] are conforming because the same letter shapes are next to each other. [cl] and [lc] are nonconforming because they abruptly change shape type halfway through the word.
The proper way to change shape mid-word is like [ccall], because [a] counts as both curve and line. [c] is comfortable to the left of [a] because it is still next to a curve. [l] is comfortable to the right of [a] because it is still next to a line. Note that [lac] and [caal] are nonconforming; words cannot switch from a series of [l]’s to a series of [c]’s, and words cannot have multiple [a]’s in a row.
[E] is “invisible” so when evaluating words, we can just delete them.
3.3.4 Real examples
Here are some real words from the beginning of f1v to help demonstrate the system. Not all of these words are conforming but these discrepancies will be explained in Part 4.
f1v word 1: “kchsy” goes [Eccc], equivalent to [ccc], which is conforming. It helps to write out the word in the original script and label each according to their shapes to understand it more easily. You don’t need to memorise which words belong to which category, just intuitively look at the base and see if it’s a curve or a line or both combined.

“kchsy” with base shapes in black and the extra parts in pale red. You can even write the word comfortably by starting with “keeee” and then adding the extra bits. Try it!
f1v word 2: “chodaiin” goes [cccalll] which is conforming.
f1v word 3: “ol” goes [cl] which is nonconforming! I’ll get to this.
f1v word 4: “olkchey” goes [clEccc], equivalent to [clccc], which is nonconformingfor the same reason.
f1v word 5: “char” goes [cal] which is conforming.
f1v word 6: “cfcar” goes [cal] which is conforming.
f1v word 7: “am” goes [al] which is conforming.
f1v word 8: “ykeey” goes [cEccc], equivalent to [cccc], which is conforming.
f1v word 9: “char” goes [cal] which is conforming.
f1v word 10: “or” goes [cl] which is nonconforming.
In this limited example we have encountered some exceptions to this rule which doesn’t sound good. Bear with me, I’ll explain those later along with the exceptions from Part 2. But first, let’s do some number crunching to get evidence.
3.4 CLS word structure test 1 – Affinity of glyph “a” (Brian Cham)
3.4.1 Hypothesis
Consider the glyph “a”. According to the CLS word structure, a [c] glyph must occur to the left and not to the right. Conversely, an [l] glyph must occur to the right and not to the left. I hypothesise that conforming combinations will outnumber nonconforming combinations in every case.
3.4.2 Method
Again I counted combinations of glyphs both before and after “a” using regexes. I did not restrict myself to word endings. Conforming and nonconforming combinations were based on the CLS word structure proposal.
Due to the small sample size of combinations, no formal statistical analyses were used.
3.4.3 Results
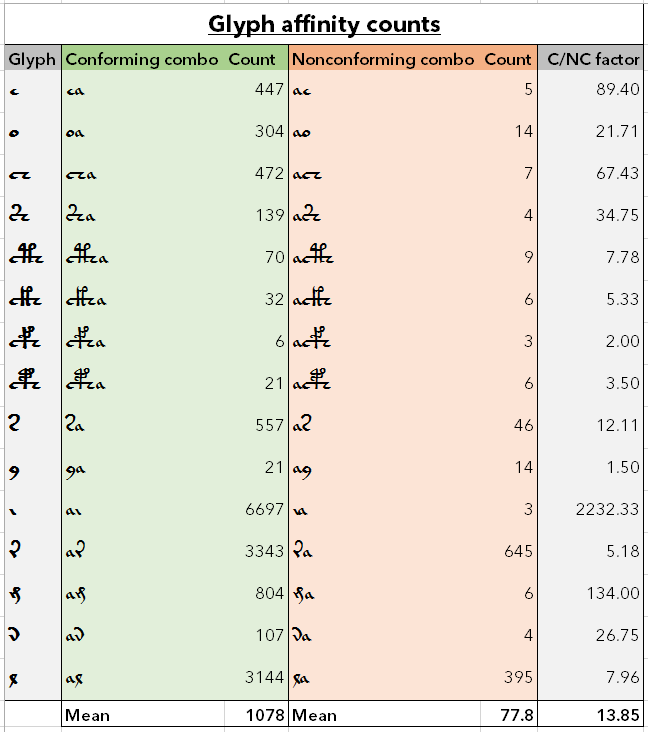
Result data table for Part 2 test 2, about glyph “a” affinity.
The sample of conforming combinations (n=15) has a mean of 1077.6 and standard deviation of 1889.844. The sample of nonconforming combinations has a mean of 77.8 and standard deviation of 185.949.
3.4.4 Interpretation
In every comparison the conforming combinations outnumbers the nonconforming combinations, confirming the hypothesis. The mean of the conforming combinations outnumbers the mean of the nonconforming combinations by a factor of 13.85. The biggest difference is “ai” vs. “ia” with a factor of over 2000. The only cases where the conforming/nonconforming factor is under 5 is when the sample size is small, i.e. under 50 words.
Based on these results, I conclude that there is a significant difference between the conforming and nonconforming “a” combinations depending on the base shape of the glyph.
However, despite this very strong pattern, we still find hundreds of nonconforming combinations. The discrepancies will be discussed and explained in full in Part 4.
3.5 Test 2 – Testing significance of CLS word structure (Brian Cham)
In this test, I calculated how well the CLS word structure applies to the whole text. More importantly, I determined whether the system achieves its fit purely by coincidence. After all, the CLS only has four glyph categories, one of which is completely “invisible” to the system. This may raise suspicions that this word system only fits by chance because there are so many glyphs allocated to each category.
3.5.1 Hypothesis
The “word-conformance rate” of a system is the percentage of words in the Voynich Manuscript’s text that conforms to that system.
Null hypothesis: There is no statistically significant difference between the word-conformance rate of the CLS compared to a randomly generated system.
Alternative hypothesis: There is a positive statistically significant difference between the word-conformance rate of the CLS compared to a randomly generated system.
3.5.2 Method
First, a Python script determined the word-conformance rate of the CLS by testing each word, adding it to the appropriate tally, and calculating the percentage once complete.
Then, a separate Python script was used to generate and test 999 random word structure systems. These systems randomly assigned glyphs to the four behavioural categories – [c], [a], [l] and [E]. To ensure that results were not skewed by having too many glyphs allocated as “invisible”, the number of glyphs in each behavioural category was restricted to the same number as in the CLS. For each system, the script tested it on the entire text using the same method as the first Python script. Once all systems were tested, the word-conformance rates were saved to a CSV file and analysed with a one-sample t-test to determine the significance of the word-conformance value of the CLS.
3.5.3 Results
The prepared transcription had 40,779 words, of which 29,151 words (71.49% to two decimal places) fitted the CLS word structure.
The sample of randomly generated systems (n=1000) had a mean of 45.58% conformance, median of 43.80% and standard deviation of 14.24% (to two decimal places).
The one-sample t-test with value of 71.49% had the following results:

Results of the one-sample t-test with value as 71.49.
3.5.4 Interpretation
The P-value 0.000 gives us very strong evidence against the null hypothesis and in favour of the alternative hypothesis, which is that the word-conformance rate of the CLS is higher than chance. The 95% confidence interval of the difference is -26.79% to -25.02% which does not overlap zero and is a large amount in context. This is a statistically significant difference at the 5% level of significance, thus I can claim that the CLS word structure fits the text of the Voynich Manuscript better than chance.
Part 4 will explain the relatively low word-conformance rate.
3.6 Test 3 – Applying the Curve-Line System to natural languages (Brian Cham)
To further investigate whether the CLS holds merit, I forced it onto natural languages to compare the results. This will help us see if the system only work because it separates common and uncommon glyphs into different categories.
3.6.1 Hypothesis
I hypothesise that when the CLS is forced onto natural languages (where it would only fit by coincidence), the word-conformance rate will be under 71.49% (the rate of the Voynich Manuscript’s text).
3.6.2 Method
Due to technical constraints, I used the texts in my natural language sample pack that were predominantly in the basic Latin alphabet (i.e. no Pinyin or Vietnamese) and of reasonable quality (i.e. excluding the academic reconstructions of extinct languages). Details of the language selection can be found in that pack.
For each language text I simply stripped away the punctuation and ran the regular CLS script on it to determine the word-conformance rate.
I also made a fake system for the Latin alphabet based on lowercase letter shapes, and tested the word-conformance rate for this.
Ascenders (surrogate for CLS category [a]) – Glyphs that stick up – b, d, h, k, l, f, t
Descenders (surrogate for CLS category [l]) – Glyphs that stick down – g, j, p, q, y
Squares (surrogate for CLS category [c]) – Everything else – a, c, e, i, m, n, o, r, s, u, v, w, x, z
3.6.3 Results
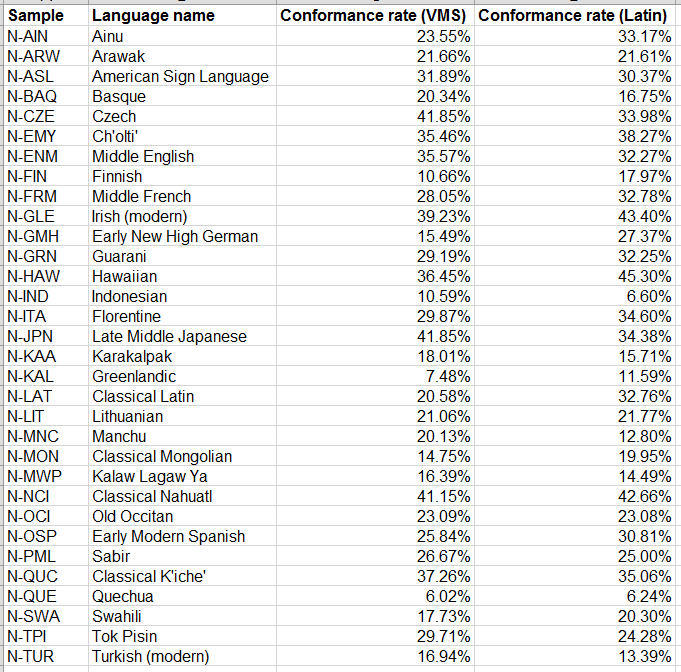
The word-conformance rates when the CLS is forced onto natural languages. The third column shows the rates for applying the pure CLS, and the fourth column shows the rates for applying the fake system for the Latin alphabet.
3.6.4 Interpretation
As predicted by the hypothesis, no natural language sample could achieve a word-conformance rate equal to or greater than the Voynich Manuscript’s (71.49%). The closest was 45.30% (Hawaiian with the fake Latin system) which was still very far away, and not a majority of words.
Since the Voynich Manuscript’s text does not seem to fit a natural language in these tests, nor is it random, then it must be artificial, in which case there is no reason for CLS not to fit.
3.7 Test 4 – Word-conformance rate of Currier language A and B (David Jackson)
This test was formulated and carried out independently. It has no specific hypothesis, it is just meant to determine how many words in the Voynich Manuscript are conforming under the CLS word structure.
3.7.1 Method
I take the Takahashi transcriptions and put into the Voynich.ninja glyph parser. I use the following rules to build up a set of words that break them:
A curve [c] glyph should never follow a line [l] glyph unless there is a certain style. I try to detect unstylistic transformations. Rules:
- (a/c) – “a” cannot precede a curve glyph.
- (l/a) – “a” cannot follow a line glyph.
- (l/c) – a line glyph cannot precede a curve glyph.
- (c/l) – a curve glyph cannot precede a line glyph.
3.7.2 Results
Note the difference between a “word” and a “distinct word”. In the phrase “I am Sam, Sam I am,” there are six words (“I”, “am”, “Sam”, “Sam”, “I” and “am”) but there are three distinct words (“I”, “am” and “Sam”).
Each distinct word has a number of occurrences, i.e. the number of times it appears as a word in the text. In the example above, each distinct word has two occurrences.
Currier Language A (10,645 words)
There are 4040 words that are deemed nonconforming, of which 1328 (32.87%) are distinct. Thus, 37.95% of words are nonconforming and the remainder 62.05% are conforming.
That sounds low, but a word that appears infrequently in the corpus is likely to be a scribal or transcription error. So what happens once I discard all nonconforming words that appear four times or fewer?
We now have just 121 words that account for 2507 of all occurrences. In other words, looking at Currier A as a whole, 9% of all nonconforming words account for 62% of all occurrences, once low frequency counts have been stripped out.
Drilling down into this list, we see that a number of high frequency words that conform to certain rules make up a large percentage of this list. For example, “chol” appears 281 times; “chor” 182 times, etc. This will not be examined further here.
Currier Language B (20,969 words)
There are 5870 words that are deemed nonconforming, of which 1877 (31.97%) are distinct. Thus, 27.99% of words are nonconforming and the remainder 72.01% are conforming.
Again I strip out all words that appear fewer than five times in the text.
I am left with 189 words that account for 3644 occurrences. In other words, looking at Currier B as a whole, 10% of all non-conforming words account for 62% of all occurrences, once low frequency counts have been stripped out.
3.7.3 Interpretation
Generally the majority of words are conforming under the CLS word conformance. It is not a large majority. However, fewer than 10% of the nonconforming distinct words in this transcription appear five times or more in the corpus.
A continuation of this test in the next part of the article yields a surprising result that may vindicate the nonconforming words.
3.8 Comparisons with previous work
At this point I will compare the CLS word structure to some other word structure paradigms. In doing so I do not presuppose that they, nor the CLS, is correct. It is also not meant to be a comprehensive list. The purpose of these comparisons is to evaluate how this might be compatible (or not) with those created independently from other core ideas.
These are presented in no particular order.
3.8.1 Comparison with Stolfi’s hard-soft paradigm
This is one of Stolfi’s older ideas before he moved onto crust-mantle-core. It is impossible to compare with the hard-soft paradigm as it is too open-ended and it can only be used to evaluate pre-existing text, rather than generating new words (the possibilities are too great). It is only noted because in spirit, it is the word structure paradigm with the most similar underlying idea, although it does not take into account glyph shape.
3.8.2 Comparison with Stolfi’s crust-mantle-core paradigm
In the three-layer model, the crust (weight 1) has [E] and [c] glyphs, the mantle (weight 2) has only [c] glyphs, and the crust (weight 3) has [l] and [c] glyphs. Many of the basic conforming crust-mantle-core distributions are also conforming curve-line patterns, but those involving cores next to mantles can result in nonconforming patterns [lc] and [cl].
In Stolfi’s paradigm, “e” only goes next to or within crust and mantle glyphs. This always results in [Ec], [cc] or [cE] which is correct under CLS.
Unfortunately he states that the distribution of “a”, “o” and “y” are too complex to be included in the model, which limits the comparisons we can make. Still, most of his general observations in this section are compatible with CLS:
- “a”, “o” and “y” usually do not occur next to each other, precluding the possibility of nonconforming [ac] or [aa].
- “a” is only allowed before the “in” groups, essentially enforcing the CLS rule that [a] must only be followed by [l]’s. However, his allowance of “oin” groups are conforming under CLS.
- Only “o” is allowed before “e” and “ee”, which are both [c], and only “o” and “y” are allowed next to core or mantle letters, which are either [E] or [c]. These essentially enforces the CLS rule that [c]’s stick together and cannot have [l] or [a] in between.
3.8.3 Comparison with Elmar Vogt’s word grammar
They are mostly compatible except for paths which contain the sequences “ol”, “or”, “lo”, “la” and “ra”. The endgroup that begins with “a” is entirely compatible but the other groups have mixed results.
3.8.4 Comparison with Phillip Neal’s Voynichese word generator
The CLS word structure is wholly incompatible with Phillip Neal’s grammar as it allows for words with every nonconforming combination – [ac], [cl], [lc] and [la]. However it must be noted that Neal’s paradigm is rather loose and allows for clearly nonconforming words such as “ddeeeeiiin”.
3.8.5 Comparison with Nick Pelling’s Markov state-machine
Note that Nick Pelling does not advocate this paradigm. It is included solely to add variety and include a state-based word paradigm in the comparison.
They are partially compatible. Pelling’s paradigm allows for nonconforming sequences like “olch” [clc], however they both agree that the other nonconforming patterns [la] and [ac] cannot occur.
3.8.6 Comparison with Tiltman’s word division
This system is not a full word paradigm, but a very rough classification of which “suffixes” go with which “roots”. They are almost completely compatible except for the suffixes “or” and “ol”.
3.8.7 Summary of comparisons
In summary, the CLS is mostly compatible with a lot of these word structure systems. The most obvious discrepancy is how they allow for “or” and “ol” to exist, and sometimes occur in front of curve vowels.
4. PART 4 – CLS mistakes
Okay, now I’ll get to explaining all of those exceptions from the previous parts.
4.1 Style of errors
If we look at these exceptions past the pure numbers, view many in context and let them marinate in our minds for a while, we see something striking.
Look at the real pictures of the manuscript pages and glance over the words and their glyphs’ base shapes. A lot of them fit the CLS (curve-line system). And sure, a lot of them don’t. But look within the nonconforming words. There’s usually only one glyph that ruins the rule. In rare cases there are two. The rest of the word fits fine.
For example, even in long words you might get nonconforming [clcccc] or [lllcll] but nothing crazy like [laccl] or [lclcla]. At worst you would get two conforming sequences stuck together like [calcall]. That’s interesting. If there was no correlation between glyph shapes and their order at all (i.e. shape-type was purely random), nonconforming words of the crazy type ought to come out just as often as the types we see, as well as everything in between. But they don’t.
Let’s prove this.
4.2 Test 1 – Number of inconsistencies within nonconforming words (David Jackson)
This test is a continuation of Part 3, test 3.
4.2.1 Hypothesis
Words that are nonconforming in CLS by a count of only one glyph will outnumber all other counts.
4.2.2 Method
Within the list of ungrammatical words I separate words that are nonconforming by one count and words that are nonconforming by more than one count.
4.2.3 Results
Currier language A
There are 4,040 invalid words in a text of 10,645. That is 37.95% of the total.
The body of 4,040 invalid words is comprised of 1,328 distinct words, a ratio of 32.87 (to 2 dp).
Of these 1,328 distinct words, 793 (59.71% to 2dp) are ungrammatical by one inconsistency, 404 (10%) are ungrammatical by two inconsistencies, 102 (7.68% to 2dp) by three inconsistencies, 26 by four inconsistencies and 3 by five inconsistencies.
Currier language B
There are 5,870 invalid words in a text of 20,969. That is 27.99% of the total.
The body of 5,870 invalid words is comprised of 1.877 distinct words, a ratio of 31.98 (to 2 dp).
Of these 1,877 distinct words, 1,116 (59.45% to two decimal places) are ungrammatical by one inconsistency, 606 (32.29%) are ungrammatical by two inconsistencies, 128 (6.82% to 2dp) are ungrammatical by three inconsistencies, 24 by four inconsistencies and 3 by five inconsistencies.
Total
Out of a total of 31,614 words tested, 9,910 are invalid. That is 31.35% of the total. The total of unique aberrant words across the whole corpus has not been tested.
4.2.4 Interpretation
Overall it is very clear that the number of words that differ by only one inconsistency outnumbers the rest combined, validating the hypothesis. Thus we can claim that the “profile” of CLS word structure errors is not random and appears to mostly be accounted by single glyphs invalidating the rest of the word.
4.3. Aberrant glyphs
In words that are nonconforming by one inconsistency, that glyph will be called the aberrant glyph.
So which glyphs are the aberrant glyphs? Are some more common than others? If it was purely random then every glyph would equally appear as the aberrant one. But they don’t.
4.4 Test 2 – Identifying aberrant glyphs using genetic algorithm (Brian Cham)
This test has no specific hypothesis, it is just meant to investigate which aberrant glyphs are the most common.
4.4.1 Method
If you don’t understand this section, just look at a summary of what a “genetic algorithm” is (link is in the title) and skip to the results.
Seeds: There are twenty initial seeds. Each one independently has an array of eight randomly assigned glyphs.
Fitness evaluation: A random sample of 1000 nonconforming words was prepared. Each seed was tested by removing all of its glyphs from the sample of nonconforming words, and the word-conformance rate of the CLS tested again. The higher the word-conformance rate, the higher the fitness of that set of eight aberrant glyphs.
Reproduction method: When all twenty seeds were tested, the ten with the highest fitness were culled and made to reproduce in random pairs. A child has two glyphs from the first parent and six from the second parent, as long as they are all still different. Then the process repeats.
Termination condition: The process stops when at least 5 sets of glyphs result in a glyph-conformance rate of 90% or above.
4.4.2 Results
After running the algorithm hundreds of times, the most common aberrant glyphs turned out to be o, a, r and l.
Manually looking at the most common nonconforming distinct words shows that the vast majority have “ol” or “or” at the beginning or end, and occasionally in the middle.
4.4.3 Interpretation
These results fit into the observation that these form the clusters “or”, “ol”, “ar” and “al”. The former two are already nonconforming under the CLS. The latter two are conforming but are often appended to other words to make them nonconforming, e.g. “arsheey”, “araiin” or “arar”.
4.5 Summary of unigram correlation study (David Jackson)
David Jackson did an independent study to see if glyphs were assigned to the correct category and look at aberrant bigrams. This section is only a summary. A link to the full article is in the afterword.
4.5.1 Terms and theory
A “rule of thumb” for transcription errors has been assumed. In essence, when an aberrant glyph has a very low occurrence (under 0.5% of the corpus) I ignore it. When such occurrences are manually checked against the original manuscript they usually turn out to be ambiguous, smudged or erroneous.
CLS glyph categories are assumed to be correct. Each glyph is then compared to the one just before or after. If any are from the opposite CLS category, this is aberrant. In doing so we can see common bigrams that break CLS and can’t be explained by transcription or scribal errors.
4.5.2 Bigrams
First, I looked into the curve glyphs. Non-conforming glyphs are shown by large yellow and green bars.
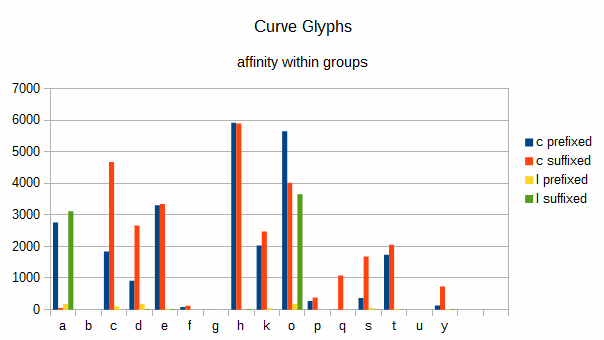
Table of concordance showing prefixes and suffixes of c glyphs
- “a” is mainly prefixed with [c] and suffixed with [l] which is expected by CLS under its rule for [a].
- “o” is suffixed by a line often.
Conclusion: “o” is non-conforming. Other glyphs behave as expected.
Next, I looked into the line glyphs. Non-conforming glyphs are shown by large blue and orange bars.
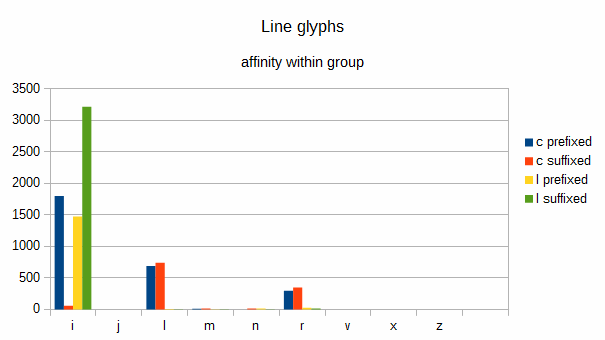
Table of concordance showing prefixes and suffixes of line glyphs
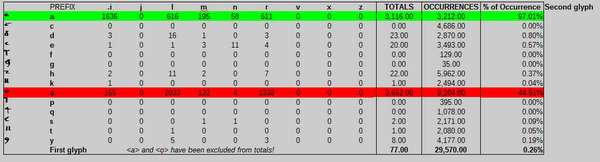
- “i” is often prefixed with a curve glyph, usually “a” (1637 times) and sometimes “o” (155 times).
- “l” is often prefixed or suffixed with “a” (“la” 233 times, “al” 75 times) or “o” (“lo” 123 times, “o” 442 times), “s” (“ls” 75 times)
- “r” is often prefixed or suffixed with “a” (“ra” 105 times, “ar”106 times) or “o” (“ro” 81 times, “or” 187 times) and “y” (“ry” 97 times).
Conclusion: “o” and “a” appear to be the main aberrant glyphs affecting the results of the line glyphs. Other glyphs behave as expected.
4.5.3 Tables of concurrence
I then drew tables of concurrences. Each had the aberrant bigrams where I checked the numbers to see which patterns were random and which had rules.
First, the aberrant bigrams with nonconforming pattern [cl]:
![Table of Concurrence: incidence of [c-l] aberrant bigrams](https://briancham1994.com/wp-content/uploads/2014/12/davids-aberrant-bigram-table-c.jpg)
Table of Concurrence: incidence of [c-l] aberrant bigrams
No real surprises here. “a” is followed by [l] frequently (97% of cases), as expected under the CLS. The only aberrant glyph here is “o”. If we exclude “o” from the results, the rate of non conformity drops to just 0.26%, as we can see in the following table (where “a” and “o” are excluded from the totals):
Then, the aberrant bigrams with nonconforming pattern [lc]:
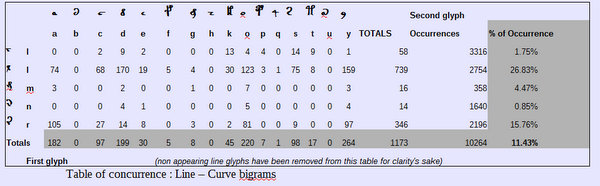 “l” and “r” are aberrant far more often than the others.
“l” and “r” are aberrant far more often than the others.
[full discussion of all the bigrams is ommitted for brevity’s sake]
4.5.4 The rules
I have identified three aberrant glyphs which only have medium or high conformity to the proposed CLS system. However, these three aberrant glyphs conform to very specific rules, and seem to be part of specific ngrams that occur due to some as-yet-unidentified, but very specific, reason.
- “o” is aberrant 44.51% of the time, when it appears in the following bigrams: “ol”, “or” and (rarely) “lo”, “ro” (where “ro” could be a confusion for “lo”).
- “l” is aberrant 26.83% of the time, when it appears in the following bigrams: “lo” (see rule 1), “ly”, “ld”. Furthermore, these two bigrams always appear in the following trigrams: “oly”, “aly”, “old”, “ald”.
- “r” is aberrant 15.76% of the time, when it appears in the following bigrams: “ro” (see rule 1), “ry”, “ra”. These last two bigrams are almost always part of the following trigrams: “ara”, “ora”, “ary”, “ory”.
4.6 Patch #1
In section 4.4 I found that the most common aberrant glyphs that ruined words were in fact the digraphs “ol”, “or”, “ar” and “al”, which all seem to be separate from the CLS and all in the same way. When these clusters make words nonconforming, it is consistently because they are in front of a curve-glyph.
In section 4.5, David found the rules behind aberrant bigrams.
There is a simple suggestion that can explain these findings and patch the low word-conformance of the CLS. Those four clusters are functionally separate digraphs with no relation to their components “o”, “a”, “l” and “r”. They act as curve glyphs in themselves. This would satisfy the aberrant bigram rules that David inferred, establish agreement with the other word structure proposals, and rectify the previous nonconforming sequences shown in the article.
The fact that these four digraphs are graphically interrelated strongly suggests that this is deliberate, meaning we can add this as an extra rule to the CLS to complete its explanatory quality.
When we consider this new part of the CLS, the word-conformance rate shoots up to 92.56%.
4.7 Patch #2
Even with that addition, the CLS is not perfect. There is still a considerable number of words that don’t fit. How could we explain these? We looked into all sorts of properties.
Manually skimming through the list of non-conforming words, David noted that almost half had “l” as the first letter. Looked like a good place to start, so I tested word-conformance rate across different beginnings of all words in the manuscript text. Most were above 90%, but there were exceptions: words starting with “l” were about 14.7% conforming and those starting with “r” were 40.8% conforming.
Could this be explained by the idea that “l” and “r” can be prefixed to a word arbitrarily? Turns out that words with these prefixes are otherwise conforming to the CLS without them, confirming my suspicion. In case anyone thinks I’m arbitrarily adding new rules to the CLS to make it fit the text, note that the glyphs “l” and “r” were part of patch #1 too – suspiciously consistent!
Now that that’s added, the overall word-conformance rate of the CLS is at 96.63%, comparable to the other word structure proposals, and is now complete.
4.8 Remaining non-conforming words
I will briefly comment on the remaining non-conforming words. What are the facts? They appear at a constant rate throughout the manuscript, and almost never recur. The word lengths appear to be a normal distribution (don’t quote me on that) with mean 4.38 glyphs. The most common non-conforming words (on, dl, chl, om, son, …) are very short.
Inevitably some will be digital transcription errors. There may also be rare scribal errors. But skimming through, a lot of the words don’t look like slight errors of possibly valid words, they look completely wrong, e.g. “dlssho”, “kydany”, “skaodar”.
If the text has meaning, they may be words in another “language” or “system”. Perhaps they are proper nouns in a straightforward substitution cipher. Perhaps these particular words were intentionally “translated” or “encrypted” a different way for some reason. Perhaps they are nulls.
If the text has no meaning, the scribes may have regularly gotten bored or lazy and made random words from the available glyphs without consulting their generation mechanism.
But who knows?
4.9 Discussion
4.9.1 Significance
The significance of this system is not simply in the numbers nor in how many words fit. Its existence is supported by the concordance of independent strands. Instead of creating a word structure paradigm that fits well but is otherwise arbitrary, this has correlation with another evident aspect of the Voynich Manuscript, the design of the glyphs.
Also, with the new patches, the word-conformance rate is extremely high and we see concordance with other word structural proposals, lending credence to the analysis. The glyphs in the exceptions to the CLS are all graphically interrelated, which is another concordance that is hard to ascribe to chance.
Most notable is that we now may be in the head of the genius/joker who sat down and designed the manuscript text 500 years ago. The concordance of the word structure with the glyph shapes, which we agree is deliberately designed, suggests that the CLS is not just incidental, it is part of the deliberate design as intended by the author. It is not just a pattern of the text, it is the pattern. This is contrasted with other statistical findings that apply modern mathematical concepts and give interesting results but obviously were not part of the original intention (e.g. I doubt a 15th century author thought “I should make the word lengths a binomial distribution and make the second-order entropy really low!”).
This gives us some grounding in the form of the true mental framework to evaluate the construction of the text. Now we finally have a real entry point. Our grappling hook has latched onto something. Now that we’re here, what can we see? A bit of intention. Whatever the manuscript “text” is, the creator intended for glyphs to be designed in a systematic way, intended some to look like syllabic blocks (or/ol/ar/al), intended for the glyph shapes to flow together in a certain structure and intended for “l” and “r” to be in the exceptions.
Make of that what you will.
4.9.2 Glyph construction
The CLS describes the reason behind the shape of glyphs (i.e., how the creator came up with the alphabet) very well indeed – he started with two basic shapes (curve and line) and then just created all the letters he needed. Add the standard tail modifiers, plumes and horizontal connectors, and you’ve got just about everything in the alphabet.
4.9.3 Practical implications for glyph identification
If correct, the CLS’s glyph construction tells us which characters are separate and which are variants, which was endlessly debated without a grounded framework. After all, someone analysing handwritten modern English might think that “+” is so rare that it must be a mistake for “t”, and “a” and “ɑ” are different characters, so intuition and frequency alone are not enough.
Are EVA “b” and “n” really the same? No, they are different glyphs.
Are “j” and “m” really the same? Yes, “j” is just an “m” where the tail accidentally connects with the base.
Are “g” and “d” really the same? No, they are different glyphs.
Is the open “g” related to “g”? Yes, they are the same, just a slight scribal variation.
With the CLS we can make those claims with a consistent basis.
Scribal quirks can also be resolved. In Torsten Timm’s paper, in which he argues that the Voynich Manuscript is a hoax, he wonders if some glyphs are invented or modified on-the-fly by the scribes. This is what he writes about “S”:

There are so many possibilities for what these little details mean (if they mean anything at all). The CLS’s focused lens answers this question by saying that “s” is by definition an “e” curve with a tail modifier on the top.
Finally, the idea that or/ol/ar/al clusters are completely separate digraphs, with no relation to components o/a/r/l, expands our understanding of the alphabet.
4.9.4 Implications for the nature of the text
The highly structured nature of the CLS suggests that the Voynich Manuscript’s text is not a natural language in its pure form, unless one could point out an example of a natural language that follows this graphical system. It would have to divide its glyphs into three or four categories in a set order. All of the glyphs in a category would have a specific visual trait in common that is not found in the other category. However the “midfix” category would combine the visual traits of the glyph categories that come before and after. The closest natural language script is Arabic, where glyphs change shape depending on their position in the word (beginning, middle or end), but there is no visual connection between the glyphs in these categories.
Instead it must be an artificially constructed and highly ordered type of information. This could range between generated nonsense, transposition cipher, artificial language and technical nomenclature.
(at this point I will not speculate about how the CLS pattern connects to the encoding/generation of these types of information. This article is just about providing evidence for the existence of the pattern in the first place, before moving on and developing the ideas further in a follow-up article)
4.9.5 CLS vs. other more complicated theories (additional message by David Jackson)
In some ways we’ve gone the opposite direction. Most other analysis build up complicated sets of ngrams based on rules. We disassemble ngrams to their existential basics….
All of which is to say that we’re back at Occam’s razor – the simplest solution is probably the correct one. Theories such as Antoine’s seem just too complicated for a medieval document and only look at the structure of the text, whereas the CLS explains both the design of the alphabet and the structure of the text.
And… CLS is compatible with most of them, because it explains away the atoms, whereas they talk about the elephants made up of our atoms!
4.9.6 Issues
Like all word structure proposals, the CLS does not have perfect coverage of the manuscript. Some glyph combinations are still nonconforming, e.g. “iro” (51), “id” (28), “ile” (10) and “ilo” (2). It also doesn’t explain the “-oin” type word endings.
We have gone at length to discuss why some text doesn’t fit, but at this point we must ask why so much text does fit. Why does the system exist at all? Why someone would create such a system? Unfortunately we do not have clear answers right now.
But even if you disagreed with everything after the introduction, I hope this theory is at least interesting and good inspiration 🙂
5. FAQ
That was really long. Could you give me a summary of the Curve-Line System?
Sure! Here’s a diagram that summarises the whole thing in an easy to understand way. Click on the image for full size.

Why did you and David test different methods, transcriptions and code? Shouldn’t you be consistent?
That’s a fair question but I didn’t choose that approach. I wanted to see if results were in concordance not only when tested by different people, but also if the entire method and transcription are different. This was done to make sure that these conclusions were not particular to the method or transcription I was using. When two people test the same thing and get the same results, there is independent concordance. When two people test the same thing using different methods, and still get the same results, there is even stronger concordance.
Shouldn’t “v” and “x” be line glyphs?
You could argue that some of the rare glyphs in the “Everything Else” category could go in a different category. However, I ignored these oddities because they are so rare that it is impossible to convincingly test these.
Doesn’t this only work because there are so many characters in the [c] category and invisible category? Furthermore doesn’t this just explain that “-aiin” and “-am” groups are suffixes, and everything else can arbitrarily occur in front of them?
That criticism only looks at the word structure (which, by itself, is very loose), but that’s only one third of the CLS. Another third is the glyph shapes and of course the last third is just how they align perfectly. There’s a reason that “a” occurs immediately before these line suffixes and also has a shape that transitions from the curves to the lines. The CLS also shows why you don’t find line glyphs interspersed throughout the word like “chlerdy” unless it’s in one of the four exception combos, so you can’t actually put things arbitrarily outside these suffixes.
How can you claim concordance between CLS word structure and glyph shapes when you had to shove in exceptions to make it fit better?
Ah, but here’s the lovely and surprising thing about the exceptions – they’re graphically interrelated too! The first patch points out the digraphs “ol”, “or”, “al” and “ar”, which are all permutations of a/o + l/r. The second patch involves the glyphs “l” and “r”, which appeared in the first patch. This all suggests that they are intentional features. Also note how conceptually simple the exceptions are.
Why don’t your natural language comparisons allocate an equal number of glyphs to each category as the CLS?
The original CLS does, which is why I tested for that too. For the fake Latin system, I can’t enforce that if I’m also enforcing glyph concordance too.
The natural language comparisons also don’t consider proportions of glyph categories and letter order in languages. For example, you have stuck the vowels – which we know are important sticky glyphs – in one category (c). In the Romance language it is unusual to see many hard consonants together, which is why conformance rate goes up with the Gaelic and Germanic languages. So you are not comparing like with like.
Given the natural differences between the Voynichese and Latin alphabets, it would be difficult to truly compare like with like. With the Latin, there are more letters and I have to keep the same proportions for each category. But I also need to make sure the categories have unique letter shapes, since that’s a core part of the theory too. By now fulfilling both simultaneously is extremely difficult, then it gets worse. The other half is the ordering of the letter categories, and how do I even make that comparable? “Q” is only at the start for English words, not many hard consonants together in Romance languages… very scant patterns to work with. So once I try to design a schema that would combine all of these, everything conflicts and the whole thing just falls down.
Perhaps the difficulty of setting up a fair comparison is itself a testament to how inherently different these text systems are.
6. AFTERTHOUGHTS
Here are some follow-up thoughts we had after the investigation. Once they are investigated, this section will link to our answers in the sequel.
- How do the shapes of weirdos fit into the CLS? (a quick manual check shows, surprisingly well)
- Are there any statistical links in the behaviour of each curve-glyph and their line counterpart, e.g. “s” and “r”?
- f68v3 begins “tchedy chepchy”, while f68v2 begins “teeody shcthey”. These have almost identical curve-line patterns [Ecccc ccEcc] and [Eccccc cccc]. Why?
- Is there any cipher or notation system that parallels the CLS?
- What’s the purpose of creating such a system and applying it here?
- Why are “l” and “r” the exception glyphs?
- Why is CLS conformance rate almost uniform across the entire manuscript? (is it actually?)
7. AFTERWORD
Written by Brian Cham on 17 Dezebre 2014. Last updated in Jong 2015. Thanks to David Jackson for helping with statistics and peer review. His own investigation into the CLS can be found here. Thanks to Prescott Currier for inspiration; Takeshi Takahashi and Jorge Stolfi for work on transcription; René Zandbergen for supplying code and peer review; and Jorge Stolfi, Phillip Neal, Nick Pelling, Elmar Vogt and John Tiltman for their work on word structure.
Update: Credit goes to Jorge Stolfi for having already figured out the glyph composition in a draft article from 2001.
Code and full datasets available on request.
As always, don’t forget to like, comment and subscribe! (am I spending too much time on YouTube? :P)

HI ; Pretty daunting for someone as dim as I am when confronted by real scholarly work. Impressionistically, though, I am very impressed; and if I understand your work this certainly suggests “intentionality” and even meaning suffuses the VMs.
I do have a couple of questions; how, for example, do you interpret the long lines of certain glyphs which run diagonally UPWARD though some text blocks? Does that fit with any statistical study?
As you may have noticed I am convinced the VMs is cartographic in nature, and I think it possible the text contains positional information as part of each folio as a “complete image”. Since I also am quite convinced of the specific locale mapped , I anticipate that eventually the text and images will explain each other……
David S.
Hello David,
It suggests intentionality at some level, but it has no bearing on whether the text contains meaning or not. Just that some effort has been put into the text’s appearance and structure, in a certain way. In terms of the nature of the text, the CLS pattern restricts the possibilities (e.g. pure natural language appears incompatible), but not enough to preclude either the “text has meaning” or “text has no meaning” hypotheses.
I am not sure exactly what you refer to with the diagonal lines of glyphs. Do you have examples? No doubt there is some statistical study about that somewhere (there is one for everything) but I have not seen it.
Hi Brian!
Your and David’s work is great. Statistics isn’t my thing, but I tried to understand your observation. I like your point about anomal nature of the VMs character “o” in a beginning of a word. Exactly! Could I ask you? Do you have a separate list of the anomal VMs words? It would be very useful. I’d like to test them with non-statistical method, but with my method of deciphering.
Yulia (YM)
Check your inbox. Revised list of non-conforming words should come today or tomorrow.
Hi Brian,
Haven’t yet time to read the article in full, just the abstract, but I believe that strategically you hit the right track. I seem to share similar suppositions, but I never took time to develop them. In fact I think the whole concept may be similar to known monastic ciphers like this one: http://www.davidaking.org/Ciphers.htm Not that plain, of course, but perhaps conceptually similar.
I will share detailed feedback as soon as I’ve read the article in full.
Hi Anton, thanks for the link. Is the Picardy astrolabe the same one that has the VMS month names?
Only few of them match (e.g. “octebre”) The month names on the astrolabe are listed in the quoted book (p. 138). The book is partly available at Google Books.
OK so I had a full glance… good work and definitely many things to think over. However, I found (to my disappointment) that the course you take is different from what I anticipated it would be. The good observation (and the most important one) is about the glyph formation: that “r” is not actually an “r”, but an “i” with a “tail” to it, likewise “s” is not an “s”, but a “e” with a tail, &c. I strongly agree with this. However, what I derive from this is quite different from what you propose.
I would suggest to consider not the “curve-line” paradigm, but the “superposition” paradigm. For a quick example, in this paradigm, the tail is not a “modifier”, it is a standalone element, and “r” is not a simple “line-glyph”, but a superposition of “i” and a “tail”. The superposition is in some cases implemented by “imposition”. For example, the tail can be imposed at the top of an “i”, and it can be connected at the bottom of an “i”. Perhaps, it can also be imposed at the middle of an “i” (you miss that). So, we have three different imposition variants of the same superposition.
The superposition principle seems to work with the “gallows” as well. Combine “q” with “k”, and you will get “t”. Combine “q” with the item which you call “modifier” from your table in section 1.2, line 2, and you’ll get a “p”. And so on. It also fits the complex “gallows benches” characters, where e.g. “cth” would be a superposition of “e”, “q”, “k”, another “e”, and a horizontal cross-bar (which I also consider as a standalone element).
As I noted in my previous comment, this superposition principle is at least known in the numeric monastic ciphering of the time.
These are just intuitive generalizations which require further research, but I don’t know if I ever come to that myself. So those who will please feel free to dig deeper.
What were you anticipating instead? Something more in line with your superimposition idea?
It’s certainly interesting, and while I don’t agree with some of the details (e.g. horizontal bar and tails as standalone rather than modifiers, since we don’t see them isolated), it still comes from the same conceptual foundation as the CLS – that the glyphs are composed of combinations of much simpler elements. The real composition may contain ideas from both proposals, but the distinction between base and modifier shapes would still be necessary because of the observation that similar base shapes cluster together in words.
Yes at first I thought that that “superposition” idea got a thorough development 🙂 which turned to be not the case. But that of course does not negate my interest in your article. I already made a lot of feedback notes, and as soon as I digest the amount of the research that you and David made, I will provide my feedback, as promised above.
Back to the “superposition” idea, note that we DO see the “tail” isolated – refer to f48v where it is encountered thrice in the leftmost “index” column (I don’t count the Arabic numbers column which was most probably left by the guy who did the pagination, perhaps in his attempt to match the Voynichese indexes to Arabic numbers). As for the crossbar, I don’t remember if I saw it isolated, but the way in which it is used sometimes suggests its “autonomous” meaning, e.g. refer to f51v, line 8, rightmost word, where it links “y” and “a” while crossing “f” in between, thus forming a most weird “bench” in composite.
Thanks Anton, will look forward.
I am aware of these instances, but they are very rare, and I deliberately analysed only the main bulk of the text, which has only “e” and “i” as clear isolated bases.
Hi Brian,
When you say “The Picardy Astrolabe” – is that the one which was brought to our notice by Don of Talahassee, or another? If so, he has made an important contribution: so many people have picked up on this one.
A question: do you think that your observations might apply to the method of writing, rather than to the informing languages? I mean – could these be conventions governing palaeography rather than the language or languages in which the text is written? I’m thinking of examples where a letter -say, the ‘s’ – takes one form in one position, but another if it occurs as first or last letter in a word. The way “s” is written in Greek is just one example of this; I’m sure you’ll know others.
Hi Diane,
Yes, I was asking Anton about the one that Don presented. The answer is a solid “yes”, it’s the Astrolabe of Berselius.
“If so, he has made an important contribution: so many people have picked up on this one.” – What do you mean? What other approaches have people in the VMS community taken with this? I’ve just read some of the book that Anton suggested, and its contents on the provenance and cipher, if that’s what you mean.
As for the paleographic suggestion, I don’t think it can be applied to the VMS text. If we assumed that idea to be true, the basic alphabet would become prohibitively small. Also, it implies that the number of curve-glyphs should be equal to the number of line-glyphs (since those inventories are just two different forms of the same letters), but that is clearly not the case. Not to mention there are only two [a] glyphs. This then gets complicated when we ask how the syllable exceptions (or/ar/ol/al) would fit into this paleography.
There are many words with only curve-glyphs, and if we consider all of them, we can see instances of “y” at the beginning of a word, “y” at the end”, “o” at the beginning, “o” at the end, and so forth, without any changes in shape. So if position is not affecting these, then what is? Only when there is an [a]-glyph leading the shapes from curvey to linear.
To resolve the “nonconforming o/r/l” of base CLS I was wondering whether instead of applying Patch #1 & #2: (A) changing {o} to the “transparent” category “E” raises the fraction of conforming words and (B) changing {o,l,r} to “E” does (and to which level, respectively)?
I have a feeling that (A) or (B) might be a more succint explanation than “#1 and #2”.
Would you care to run these tests?
If recategorizing “o” as a transparent letter would raise the conformancy level to >92% levels, that would be quite satistfactory, as I cannot explain/understand why “r” and “l” would be special, but not “s” and “y”? Their special behaviour completely ruins the basis you started off: namely that all the non-gallow characters (except rares and weirdos) {s,r,g,m,b,n,y,l} are basically e/i with one of four “diacritics”.
Also note that “o” is a very special character insofar, that its second stroke is *unique*, there is no character which has i (instead of e) as a first stroke and the second stroke (the inverted e) as its second component. This would warrant its “transparent” nature.
I’d also be quite happy to receive your data and programs, so I could play around with testing such hypotheses and the like.
Hello Szabolcs,
David J. has already played around with the idea of “o” as transparent (among other things), and made some scripts to test that, so you would be better off asking him for it. It did raise the conformance rate (I don’t remember the value exactly) but I didn’t like that explanation as “o” is so common that of course making it transparent would increase conformance.
Making {o,l,r} transparent would still leave the [a] glyphs in “al” and “ar” stuck in the middle of words, which doesn’t help conformance.
I don’t know why “l” and “r” are special exceptions, and I readily accept that theoretically “s” and “y” should also have some special properties under the proposal too, but they don’t. Your point about “o” being graphically unique is interesting, but I don’t think that observation alone is enough of a basis to hypothesise anything about its textual “role”.
I have just seen this, having recently come back to Voynich matters after a long period working on other things, and it is an excellent piece of work. You don’t have much to say about the position of the [E] class glyphs within a word – the strong preference of q for initial position followed by o, the preference of the gallows for medial position etc. This was the motivation of my word grammar based on slots, but I am not committed to it.
Hello Brian,
Do you allow me to cite your article, as well as include some images from it, in an article I’m planning to publish? You’ll be credited, of course 🙂
Friendly yours
Hello Dwayn,
Go right ahead. I look forward to hearing about it!
Hello Brian! I’m back with the article I told you about. You can read here the submitted draft: https://osf.io/npevw/ . This is basically about confirming the CLS, as well as giving some methodological rules to VMS research.
All your remarks would be welcome – my email address is in the paper 😀 . I hope you’ll like it