Redirect: This flag design is now hosted on this page.
Author: briancham1994
Top 50 New Zealand flag proposals (according to me)
FlagsNote: This post features my own judgement on the best flag designs. For the proposals that are most popular with the general public, see this post.
Now that the New Zealand government has closed submissions for a new flag, I decided to go through and pick out the best. That’s right, I looked through all 10,293 of them. Don’t worry, it only took me 48 minutes to evaluate (about 0.28 seconds per flag; thank god for learning scanning techniques).
It probably helped that the whole gallery was a beautiful testament to Sturgeon’s Law (in this case more like 99% though), Poe’s Law and the futility of crowdsourcing design, making it easy to mentally filter out the crud and parodies. You wouldn’t believe the Nazi, apartheid, North Korea, Israel, PRC, Imperial Germany, Quebec (of all places), meme and My Little Pony based parodies that got through their filters. Seriously, the name “Moswald Osley” didn’t ring any alarms? Well done to the Lautaro joke for subtlety and this thing for sheer insanity though. All in all, an experience I would not recommend. [2026 update: those links are all now broken, probably for the better]
I automatically dismissed any jokes, offensive statements, political statements and anything too similar to another national flag, no matter how well designed or New Zealand-y it was. I hope the judging panel can do that, but since it has no vexillologists (flag experts) I don’t have a lot of faith.
Anyway, here are the best I picked out, emulating the judges’ process of picking an initial list of 50-75 best designs. There were a lot of duplicates and near-duplicates so it’s hard to know exactly how to count and credit them (I’m sure I’ve missed a few credits, sorry!), but it should be around 50 some way or another.
This list is in no particular order.
Proposed flag of New Zealand (Silver Fern with Red Stripe)
FlagsRedirect: This flag design is now hosted on this page.

[ABERIL FOOLS] Zandbergen’s Deceit: A Complete and Holistic Explanation of the Voynich Manuscript
Voynich ManuscriptDisclaimer
This article was my April Fools joke for 2015, kept here for personal history and amusement. No, I don’t believe that René Zandbergen forged the Voynich Manuscript. And don’t worry, I’m still sane!
Introduction
In 2008 I became interested in the Voynich Manuscript and have been reading about it ever since. Over time I read many theories and went through different theories of my own, but one thing always got in the way – it just didn’t make sense. Like the mythical hydra, solving one issue would just raise more. Basically: the more you know, the more you don’t know. How could we possibly explain this artifact where no theory covers everything and the facts can contradict? Every now and again I felt a nagging gut feeling that something just didn’t add up. Something is just fundamentally wrong about the situation that I can’t put my finger on. It’s something that everyone here is thinking but nobody wants to say. We aren’t just on the wrong track, we are in completely the wrong field.
Eventually I gave in to these intuitions and started afresh with a blank slate. I cleared away all speculation, binned my previous work, disregarded the big names and ignored any assumptions and preconceptions that were holding me back. It was time for the bare facts, and the facts only. I built these basic truths into a new explanation without trying to prove any theory, trying to gratify myself, or considering what theories were popular. The result surprised and disappointed me. But the truth is the truth, it just is what it is, and it doesn’t change to comfort anyone. If you can’t face opposing viewpoints and prefer to hide within your own comfortable theories, I warn you not to read further.
I tried so hard and got so far, but in the end it doesn’t even matter. In short: The Voynich Manuscript is a modern forgery by René Zandbergen.
Welcome! I’m Brian Cham, an award-winning Vexillologist, Software Engineer, Filmmaker, Cryptographer, Bookworm, and Designer. I’m passionate about exploring diverse fields to create, educate and inspire. Discover more about me:
Vexillologist (flag expert)
YouTube Co-ordinator and Flag Design Consultant for North American Vexillological Association
💪 Served as expert design advisor for many official US state and city flag redesigns, e.g. Utah, Minnesota, Maine, Illinois and Massachusetts. For Utah, I helped to define the specifications. For Minnesota, I made critical design developments to the finalist designs with local collaborators, and was the first to conceive the specific design variation that is now the official state flag of Minnesota. For my continued and successful engagement, I won NAVA’s Vexillonnaire Award (the “Oscar of vexillology”), and have been interviewed by Reuters and Toronto Star.
💪 I have chaired several official flag design committees: NAVA 58 and 59 annual conference flags, and Boca Raton, Florida.
💪 For NAVA, I curate a rich library of video content and host the Flag Design Forum to unite our design enthusiasts and help improve real flag projects.
🎙️ I published and presented an award-winning analysis of New Zealand’s unsuccessful national flag referendum and its valuable lessons for future flag efforts, influencing multiple US state and city redesigns since then.
🏆 My work in flag redesigns have been well-received, winning public polls for Australia, Idaho, Louisiana, Massachusetts and Aotearoa New Zealand. My Earth flag design was featured in NAVA’s newsletter, and fans worldwide have manufactured and flown my designs.
🤝🏻 I’m a member of NAVA, UK’s Flag Institute and the New Zealand Flag Association. I have completed graphic design commissions like the flags for the NeuroSpasta role-playing game.
🔗 Join me in my quest for better flag design. Explore my flag projects and see my NAVA profile.
Software engineer
Software Development Engineer (ex Amazon)
💪 At Vista, I developed Living Ticket, the digital cinema ticket solution now standard in millions of cinemas worldwide.
💪 Work experience at Amazon Web Services (largest cloud provider in the world), Vista (delivers software to most of the world’s cinemas), Southern Cross (largest health insurer in Aotearoa New Zealand) and Intergen (nationwide software services).
🏆 Top paper at international conference for my university engineering project, an innovative tool promoting interactive learning of model-driven development. Published in the International Journal of Software Engineering and Knowledge Engineering.
🎓 Degree in Software Engineering from the University of Auckland, Professional Certificate in Data Science from Harvard University and two Microsoft Certifications (Azure Fundamentals and Azure Developer Associate).
🔗 Join my drive to impact the world through code. Explore my software projects and connect with me on LinkedIn.
Filmmaker
Screenwriter for Psych2Go
💪 Screenwriter for Psych2Go, a animated series promoting awareness of psychology and mental health. We have 12.7 million subscribers and counting.
🏆 Was finalist in international film competition spearheaded by the United Nations, marking recognition on a global stage.
🎙️ Was a voice actor for a BBC documentary, highlighting my versatility in media production roles and an affiliation with a renowned global broadcaster.
✍🏻 I attained 40 achievement badges (including “Top Reviewer”) on IMDb and authored over 1600 film reviews.
🎓 Degree in Film, Television and Media Studies from the University of Auckland with First in Course awards for FTVMS300 (New Zealand Film), FTVMS327 (Comics and Visual Narrative), and FTVMS212 (Video Game Studies).
🔗 Join my passion to inspire the soul and transport us to new realities. Explore my film portfolio, IMDb filmography and IMDb user profile.
Cryptographer (code breaker)
💪 I analyse the Voynich Manuscript, a centuries-old enigma that remains undeciphered. My meticulous analysis and research contributions have earned citations in scholarly papers.
💪 For the University of Auckland, I developed interactive apps to teach cryptography and steganography to students in a fun way. These innovative tools have been used as educational resources by the University of Auckland and the Museum of Transport and Technology.
🔗 Join my love of uncovering secrets and mysteries. Explore my Voynich Manuscript articles and see my Voynich Ninja profile.
Bookworm
💪 I am an avid reader, with over 500 book reviews on Goodreads and a goal to read a hundred books each year.
🏆 Was once the #1 top book reviewer in New Zealand for All Time on Goodreads.
🔗 Join my love of new worlds and ideas. Explore my Goodreads profile.
Freelance graphic designer
💪 I used to be a freelance graphic designer.
🔗 Join my enthusiasm for effective designs. Explore my design projects.
Minerva mysteries
Voynich ManuscriptRecently on the Voynich Manuscript mailing list there has been a kerfuffle over a supposed Athanasius Kircher booklet find in Minerva Auctions’ catalogue. You can find the details summarised here in Ellie Velinska’s blog (don’t worry, the April Fools’ joke at the bottom is on her part, not Minerva’s). I’ll continue with what I’ve dug up.
Hidden numbers and letters on f71r
Voynich ManuscriptHere is Bunny’s find of possible hidden numbers and letters in the tree on f71r of the Voynich Manuscript (link goes to original image). It is reproduced on my site with permission (by request, in fact).

Possible hidden letters and numbers in the tree in f71r.
Adjustments in the image: “changed contrast brightness, gamma, colour then made b/w. attempting to remove green from tree and clarify what left, no adjustments made to actual lines of image.”
Countries and territories by most popular Wikipedia edition
UncategorizedI was in a statistical geography mood so I made this map based on Wikimedia statistics. It shows the most popular Wikipedia language edition for each countries and territories that had hits in 2014 Q1. If the majority of hits from a place are for a single language, I marked that language’s colour. If there was no majority language, I marked the top two in a gradient.
I hope you find this as interesting as I did.
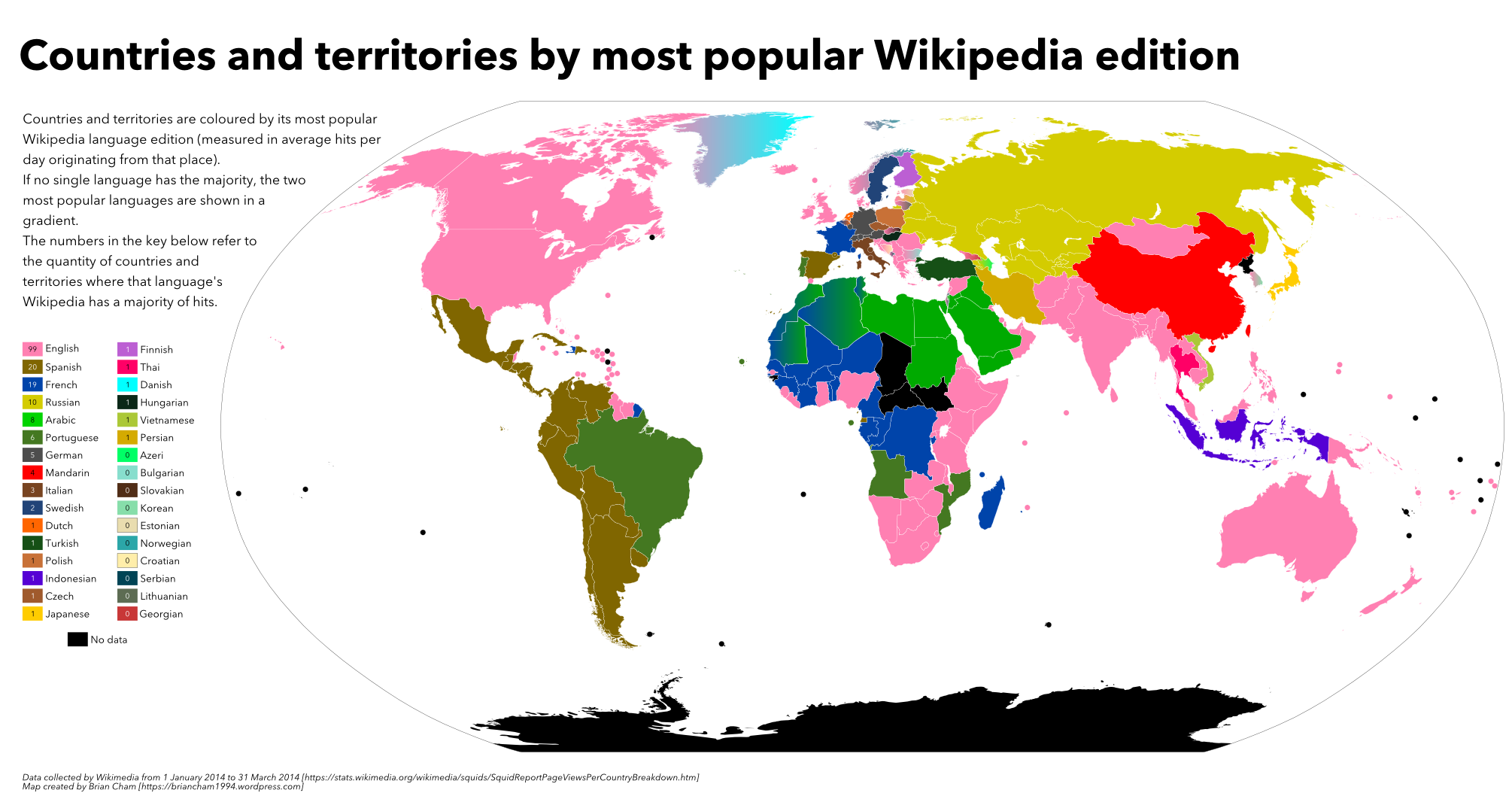
Map of countries and territories by most popular Wikipedia edition (2014 Q1). Click on image for full size.
Interesting points:
- Out of ~6000 languages in the world, only 32 (0.5%) account for most popular Wikipedia edition in every country and territory in the world that tried to access it. All of these languages are from Eurasia, which really says something about the power structures over history and the digital divide.
- Language geography corresponds well with European imperial holdings with some exceptions. Who would have guessed that Puerto Rico, Suriname and East Timor would have English as their preferred Wikipedia language? Regionalisation is also a factor.
- English has more popularity than the rest of the languages combined.
- Regions with no single majority language include North Africa, the Caucasus, the Balkans and the Baltics. Other such places include Belgium (French and Dutch), Norway (English and Norwegian), Greenland (English and Danish), Israel (English and Hebrew) and South Korea (English and Korean).
Leave your thoughts in the comments section below!
Protected: Jobs’ other finds (UNFINISHED POST)
Voynich Manuscript
Cod. Sang. 754 and the Voynich Manuscript
Voynich ManuscriptEvery now and again we uncover manuscripts with possible direct or indirect links to the Voynich Manuscript. They might contain a similar glyph, a similar illustration, or perhaps a similar diagram. A good example was Cod. Sang. 839 (discovered by Thomas Sauvaget) with the same quire number style.
Cod. Sang. 754 is perhaps special in how many similarities there are.
All credit to the discovery goes to Job (from the Voynichese project); I am simply documenting it for him. I will avoid making any bold claims and simply lay out all the similarities and let you make your own decision. I’ll also not bore you with the details of the manuscript until the end.
1. The illustration
The first thing Job noticed was the style of the illustration on page 164.

Page 164 of Cod. Sang 754.
It should speak for itself.
(it’s the only full plant illustration in the manuscript so don’t bother looking for others)
